课程概述
在现代游戏引擎中,渲染系统(Rendering System)占据着极其重要的地位。它不仅占据了引擎代码量的最大部分,也是技术难度和专业壁垒最高的领域之一。虽然很多人认为"游戏引擎只是一个画图引擎",但实际上游戏引擎的渲染与教科书上的计算机图形学有着本质区别。
游戏渲染 vs 理论图形学
计算机图形学理论关注的是:
- 特定效果的正确性(如透明物体折射、水体渲染、毛发算法等)
- 算法数学上的精确性,不考虑硬件实现细节
- 可以花费几分钟甚至几天渲染一帧(离线渲染)
游戏引擎渲染面临的四大挑战:
- All-in-One的复杂性:一个场景需要同时处理水体、植被、毛发、皮肤、云层等不同效果的数千个物体,所有算法必须集成在一个容器中协同工作。
- 深度硬件适配:算法必须在当代硬件(PC、主机、移动设备)上高效运行,需要对GPU架构有深入理解。
- 固定预算约束:必须在严格的时间预算内完成(30fps ≈ 33ms/帧,60fps ≈ 16ms/帧,电竞要求120fps+)。无论场景是密闭小房间还是开阔城市,帧率必须稳定,绝不能出现"开门掉帧"的情况。
- 资源受限:渲染系统通常只能占用CPU 10-20%的资源,其余要留给游戏逻辑、物理、网络等系统。 因此,游戏引擎的渲染系统是工程实践科学,是过去30年行业迭代优化出的重度优化的软件系统,而非单纯的理论模型。
因此,游戏引擎的渲染系统是工程实践科学,是过去30年行业迭代优化出的重度优化的软件系统,而非单纯的理论模型。
基础渲染管线
从数据转为可见的图像的过程:
顶点 $\rightarrow$ 面 $\rightarrow$ 投影矩阵 $\rightarrow$ 光栅化像素点 $\rightarrow$ 材质/纹理 $\rightarrow$ 图片
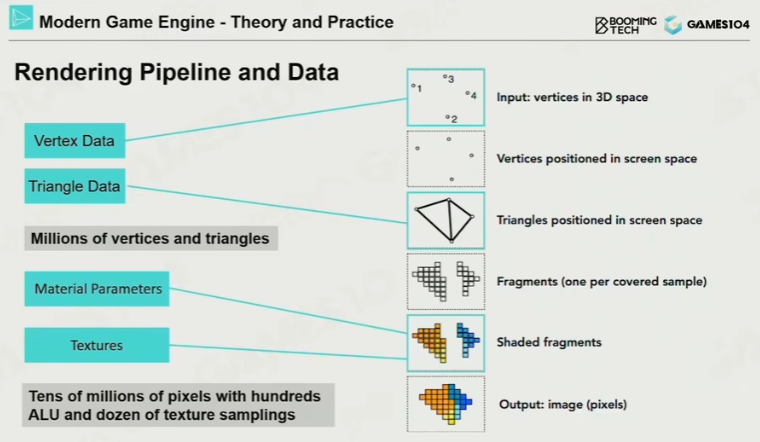
整个渲染模块分为四部分:
- 基础篇:GPU硬件架构、渲染数据管理、可见性裁剪等基础概念
- 光照与材质篇:现代光照模型(IBL)、PBR材质系统、Shader模型
- 子系统篇:地形系统、天空系统、后处理系统等
- 渲染管线篇:延迟渲染(Deferred Shading)等高级管线设计
GPU架构基础:理解硬件是优化的前提
要成为一个优秀的图形程序员,必须深入理解GPU架构。现代GPU与CPU的设计理念截然不同。
CPU:每个核心强劲,数量少,适合处理复杂的计算任务,如游戏逻辑、物理模拟等。
GPU:每个核心较弱,数量多,适合处理大规模并行计算,如渲染像素。
GPU并行架构特性
现代GPU的核心特点是大规模并行计算,拥有大量小核心。这一架构决定了渲染系统的设计哲学:
- 数据并行性优先:将复杂任务分解为大量简单、一致的计算单元
- 计算前移:尽可能将运算从CPU转移到GPU
- 批处理思维:减少Draw Call,一次设置多次复用
SIMD与SIMT架构
SIMD(Single Instruction Multiple Data,单指令多数据):
- 一个指令同时处理多个数据(如4D向量的XYZW同时运算)
- 现代CPU也广泛支持(如SSE指令集)
SIMT(Single Instruction Multiple Threads,单指令多线程):
- GPU的核心思想:将计算单元做得很小,但数量极多(数千个)
- 一条指令可以在成百上千个核心上同时执行同样的操作
- 现代GPU算力可达10+ TeraFLOPs,远超CPU(通常<1 TeraFLOP)
TeraFLOP:每秒万亿次浮点运算,$10^{12}$ 次浮点运算(FLOP),$10^{15}$ 次双精度浮点运算(DFLOP)
现代GPU硬件结构(以NVIDIA Fermi架构为例)
GPU由多个GPC(Graphics Processing Cluster,图形处理集群)组成,每个GPC包含:
- SM(Stream Multiprocessor,流式多处理器):包含数十个CUDA核心,执行数学运算
- 专用硬件单元:
- Texture Unit:专门处理纹理采样(带有滤波和Mipmap)
- SFU(Special Function Unit):处理三角函数等复杂数学运算
- Tensor Core(安培架构后):AI计算
- RT Core:光线追踪加速
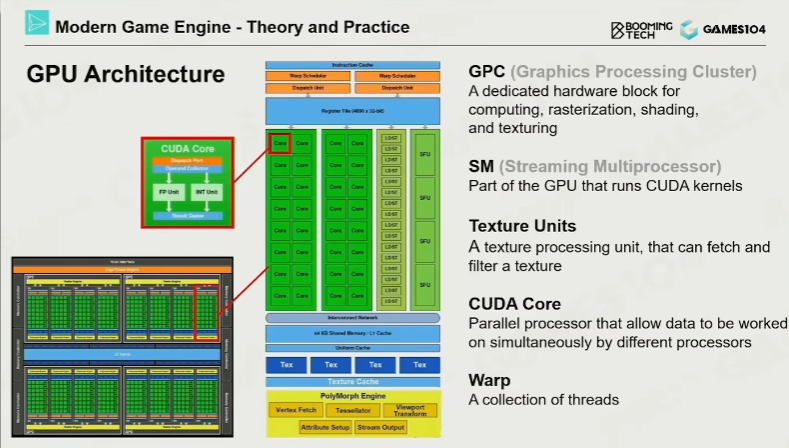
内存架构与数据流
冯·诺依曼架构:计算和数据分开,会导致数据搬运成本较高。
关键概念:
- 显存与内存:CPU内存到GPU显存的传输是主要瓶颈,必须遵循数据单向传输原则(CPU→GPU,尽量避免读回)
- Cache(缓存):现代计算性能的关键。访问主存可能需要100+个时钟周期,而访问缓存只需几个周期
- Cache Hit:数据在缓存中,快速访问
- Cache Miss:数据不在缓存中,需要等待
- Bandwidth(带宽):渲染中的常见瓶颈,包括纹理带宽、顶点带宽等
渲染数据组织:从逻辑对象到可绘制实体
游戏中的GameObject(如一辆车、一个角色)是逻辑对象,本身无法直接绘制。需要通过Renderable(可绘制对象)来表达。
Renderable的组成
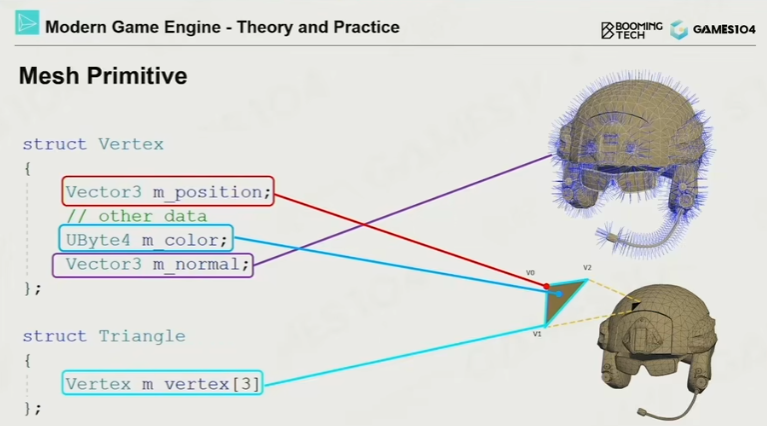
要绘制一个物体(Renderable),一般需要:
- Mesh(网格):顶点数据、三角形索引
- Vertex Data:顶点位置、法线(Normal)、UV坐标等
- Index Data:三角形索引,复用顶点以节省内存(通常顶点数约为三角形数的一半)
- Triangle Strip:一种优化的顶点存储方式,提高Cache友好性
重要提示:顶点法线必须单独存储,不能简单通过三角形面法线平均计算。例如立方体的棱角处,同一位置的顶点需要存储多个不同方向的法线。
- Material(材质):
- 表达物体表面属性(金属、塑料、石头等)
- 现代引擎使用PBR(Physically Based Rendering,基于物理的渲染)模型
- 注意与Physics Material(物理材质)区分:前者用于视觉,后者用于摩擦系数、弹性等物理属性
- Texture(纹理):
- 材质会引用纹理来采样,一个材质可能引用多个纹理,同一个纹理也可能被多个材质引用
- 不仅存储颜色(Albedo),还存储粗糙度(Roughness)、法线(Normal)、金属度(Metallic)等
- 纹理采样是昂贵的操作:单次采样需要访问8个像素并进行7次插值(考虑Mipmap和双线性过滤)
我已经有一张 Texture 了,为什么还要 Material?
因为 GPU 不知道:- 这张图是颜色?法线?还是粗糙度?
- 要不要参与光照?
- 是透明还是不透明?
- Gamma / Linear 怎么处理?
Material 就是告诉 GPU 这张图该怎么解释、怎么参与计算
- Shader Code(着色器代码):
- 独特的"代码即数据"存在:既是源代码,又被当作数据资源管理
- 现代引擎支持Shader Graph,允许美术像搭积木一样组合材质逻辑,自动生成Shader代码
SubMesh:资源复用的关键
SubMesh概念
一个面片可能包括:
- 顶点
- 朝向
- 颜色
一个复杂模型(如士兵)的不同部分(头盔、布料、皮肤、武器)需要不同的材质。
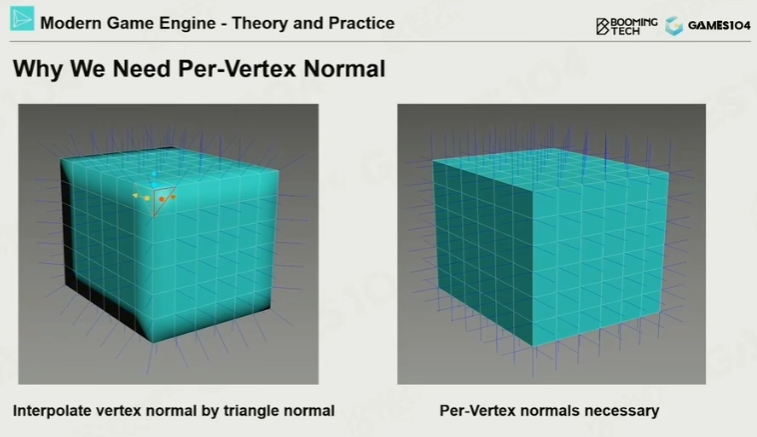
为什么每个顶点都需要存法线,而不是直接通过三角形面法线平均计算?
- 物体表面是连续曲面并不是三角形,因此以三角形算会产生跳变
- 一个像素只属于一个三角形,并不能知道周围有哪些面
- GPU的插值是顶点级别的,因此对于法线需要记录在顶点上
顶点法线 = 相邻三角形面法线的加权平均(通常权重为三角形面积),再归一化
- 将Mesh按照材质切分为多个SubMesh
- 所有SubMesh共享同一个Vertex Buffer(顶点缓冲区)/Index Buffer(索引缓冲区),但各自记录Offset(偏移量)范围
- 每个SubMesh对应特定的材质、纹理和Shader
优势:
- 内存效率:多个物体共享相同的几何数据
- 渲染优化:按材质排序后批量渲染,减少状态切换
- 工业标准:虚幻引擎等主流引擎均采用类似结构
资源池(Resource Pool)设计
现代引擎通过资源池解决数据冗余问题:
- Mesh Pool:统一管理所有网格数据
- Texture Pool:纹理跨物体共享(如多人角色的皮肤、服装)
- Material Pool:材质实例化系统
渲染优化策略
- 材质排序:将相同材质的SubMesh分组,减少GPU状态切换(State Change)的开销
- Instance(实例化):相同几何体(如小兵、树木)只存一份定义(Definition),通过实例数据(位置、旋转等)绘制多个副本
- GPU-based Batch Rendering:现代引擎使用GPU计算着色器一次性处理大量相同物体的绘制,进一步减少CPU提交开销
GPU Based Batch Rendering
对于大量重复物体(树木、草丛、建筑),传统方式需要为每个物体设置一次VBO/IBO。现代技术利用Computer Shader实现:
- 单次Draw Call渲染数百个实例
- GPU端实例化:将位移数据作为缓冲传入,GPU并行计算每个实例的最终位置
- 适用场景:大规模植被、建筑集群、粒子系统
从CPU到GPU的运算迁移
核心理念:将原本CPU负责的复杂运算迁移到GPU
- 动画系统:骨骼动画计算GPU化
- 物理模拟:粒子、布料模拟
- 可见性判定:Occlusion Query、Frustum Culling
性能优势:GPU并行算力通常是CPU的10倍以上,适合处理大规模数据。
可见性裁剪(Visibility Culling)
渲染优化的最高境界: “Do Nothing” ——通过算法让计算机尽可能少做事情。
基础裁剪方法
视锥裁剪(View Frustum Culling)
使用Bounding Volume(包围盒)快速判断物体是否在相机视锥内
包围盒类型:
- Bounding Sphere:测试最快,但包围松散
- AABB(Axis-Aligned Bounding Box):轴对齐包围盒,只需存储两个顶点,计算效率极高
- OBB(Object-Oriented Bounding Box):物体对齐包围盒,更贴合但计算复杂
- Convex Hull(凸包):物理计算中常用

空间加速结构
- 四叉树/八叉树:适合静态大场景
- BVH(Bounding Volume Hierarchy):树状结构,适合动态场景(物体移动频繁的FPS游戏)
BVH(Bounding Volume Hierarchy)
适用场景:动态物体多的场景(如RTS游戏中的大量单位)
原理:
| |
- 层级包围盒:自顶向下测试,不可见的节点整枝裁剪
- 动态重建:BVH在物体移动时重建成本低,适合动态场景
PVS(Potential Visibility Set)
思想起源:John Carmack在Doom/Quake中的开创性工作
核心原理:
- 将空间划分为Portal(门窗)连接的Cell(房间)
- 预计算:每个Cell记录从该位置通过Portals能看到哪些其他Cell
- 运行时:只渲染当前Cell的PVS中的物体
现代应用延伸:
- 关卡流送(Level Streaming):开放世界分Zone加载
- 资源预加载:通过PVS预测玩家即将进入的区域,提前异步加载资源
- 尽管纯PVS裁剪已少用,但其思想指导资源调度
GPU Based Culling
现代硬件性能使得部分裁剪可直接在GPU完成,利用GPU并行计算能力,将数千个物体的包围盒测试并行化。
- Occlusion Query:GPU返回可见性0/1数组
- Early-Z / Hi-Z:硬件级深度测试,被遮挡像素不执行Fragment Shader
- Compute Shader Hierarchy:在GPU构建BVH并并行裁剪
纹理压缩技术
纹理压缩是引擎资源系统的重要模块,直接影响显存带宽和加载性能。
纹理压缩格式
游戏引擎的特殊需求与普通图片压缩(JPEG)不同,纹理压缩必须支持:
- 随机访问:快速读取任意纹素
- 实时解压:解压开销极低
- 固定压缩率:显存占用可预测
Block-based Compression(基于块的压缩)
核心思想:将纹理分割为4×4或更大块,独立压缩每块。
- 将纹理切分为4×4像素的小块
- 记录块内颜色最大值和最小值,其他像素存储插值比例
DXT/BC系列(PC/主机):DXT1/3/5,BC1-7,支持实时压缩/解压
ASTC(移动设备):支持非方形块(如4×4、6×6、8×8),压缩率更高但压缩计算较复杂
资产生产管线
现代游戏资产来源多样化,推动渲染技术进步:
| 制作方法 | 工具 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 手工建模 | 3D Max, Maya, Blender | 基于点线面的精确建模,灵活可控 | 耗时费力 | 机械、建筑 |
| 雕刻建模 | ZBrush | 像雕塑一样自由添加细节,高度自由 | 难以参数化 | 角色、生物 |
| 3D扫描 | RealityCapture | 通过摄影测量法获取,超高精度 | 需实体原型 | 文物、写实道具 |
| 程序化生成 | Houdini, AI | 基于算法自动生成,批量高效 | 控制难度大 | 地形、植被 |
趋势:AI生成技术将艺术家从繁琐细节中解放,专注创意本身。
现代渲染管线发展方向
技术不断在进步,渲染管线也在演进,需要开发者不断学习。
Cluster Based Mesh Pipeline
驱动力:开放世界导致数据量增长10倍以上,传统管线(CPU准备顶点数据→提交GPU)无法承载。
核心思想:
- 将高精度模型拆分为固定大小的Meshlet(32-64个三角形)
- Mesh Shader:GPU根据算法和数据"凭空"生成几何细节,无需CPU预准备顶点Buffer
- Amplification Shader:决定哪些Meshlet需要细分(基于距离LOD)或剔除
- GPU-driven:所有裁剪、LOD选择、剔除完全在GPU完成,CPU只提交高级命令
优势:
- 支持像素级几何密度(如虚幻引擎的Nanite)
- 细粒度剔除:可以只剔除怪物的一只手,而非整个模型
- 艺术家无需考虑 polygon budget(多边形预算),可自由使用亿级面片模型
代表技术:
- Ubisoft 2015:《刺客信条:大革命》首次大规模应用Cluster Based Mesh Pipeline
- Unreal Engine 5:Nanite虚拟几何体技术,实现"像素级网格密度"
对开发者的要求:
- 更深入的GPU架构理解
- 更复杂的Shader编程模型
- 但换来极致的细节表现力
管线演进总结
| 阶段 | 技术 | 特点 |
|---|---|---|
| 传统管线 | VS+PS | 预构建Vertex/Index Buffer |
| 中级管线 | Hull/Domain/Geometry Shader | GPU端细分几何 |
| 现代管线 | Mesh Shader | 完全GPU驱动,动态生成几何 |
核心认知框架总结
四大核心理念
硬件驱动思维
- 渲染是工程科学,深度依赖GPU架构理解
- 熟悉"性能瓶颈"语言:带宽、填充率、ALU利用率
数据关系思维
- 核心解决Mesh、SubMesh、材质、Shader的关系
- Instance化是资源管理的通用模式(声音、粒子、植被)
极致裁剪思维
- 优化=让计算机做最少的事(Do Nothing哲学)
- Visibility是渲染性能的第一要素
GPU Responsibility思维
- GPU Driven:将CPU逻辑迁移到GPU
- 未来趋势:动画、物理、AI全面GPU化
给开发者的建议
- 渲染管线选择:自研引擎应遵循行业标准,避免过度创新导致维护困难
- Debug方法论:
- 图形Debug难度极高(仅次于服务器)
- 分步验证:将算法拆分为多步,每步单独验证
- 利用厂商工具:NVIDIA NSight、AMD Radeon GPU Profiler
- 学习路径:先读代码、加断点理解流程,再动手修改
游戏引擎渲染系统是连接硬件与艺术的桥梁,既需要扎实的工程能力,也需要对美的感知。理解硬件、优化数据、极致裁剪、拥抱GPU,这四大原则将贯穿整个渲染模块的学习。下一节课将深入光照模型与PBR材质系统,探索如何让画面"看上去像行货"。
游戏引擎的渲染系统是一个高度practical的工程事件——它不是追求理论最优,而是在硬件限制、开发效率、画面质量之间找到最佳平衡点。